Solr搜索引擎第二篇-单机安装、基本使用
本文共 1776 字,大约阅读时间需要 5 分钟。
文章目录
单机安装
Solr版本:7.5.0
下载地址: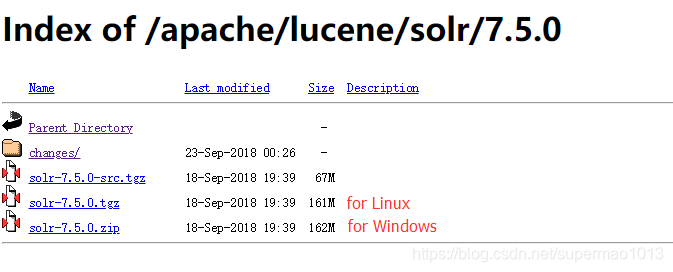
windows下安装
第一步:安装JDK1.8
第二步:解压到指定即可使用,非常简单
- 使用Solr前需要对使用的环境进行评估,是在独立的机器上部署单应用服务、还是需要分布式集群
- 考量因素:文档的数量、结构,要存储的字段数量,用户数量,影响硬件规模的因素
- Lucene严格限制:单个索引中的最大文档数大约为21.4亿
- 实际中不可能在单个索引中达到这个文档数量级还运行良好,在到达这个数量之前早就会用分布式索引集群。如果在部署时,就能估计出将达到如此量级,就应该用solrCloud分布式集群方式安装
第三步:启动
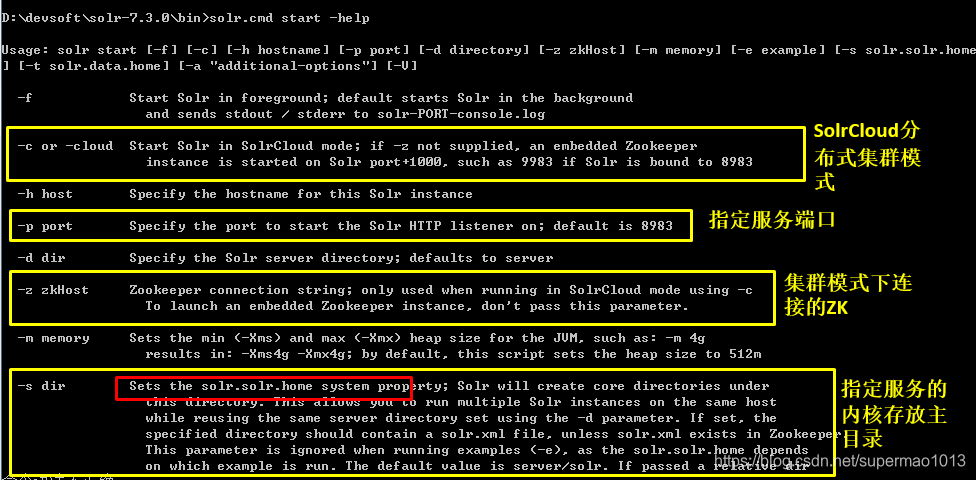
#启动,默认端口8983bin/solr.cmd start#指定启动bin/solr.cmd start -p 8984#查看状态bin/solr.cmd status#查看帮助bin/solr.cmd
Linux下安装
第一步:安装JDK或OpenJDK1.8
第二步:解压tar zxf solr-7.5.0.tgz
第三步:启动
#启动,默认端口8983bin/solr start#指定启动bin/solr start -p 8984#查看状态bin/solr status#查看帮助bin/solr
第四步:访问
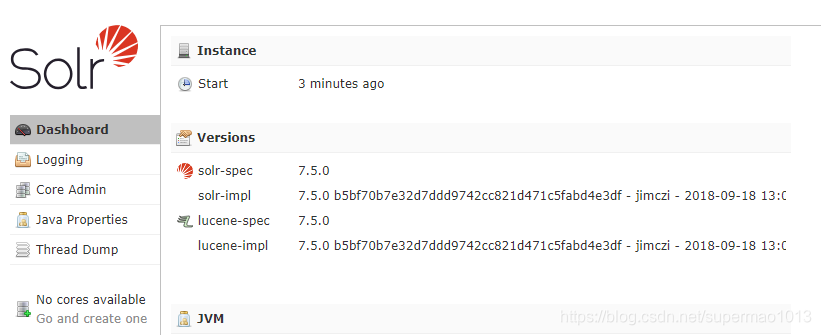
- Dashboard:仪表盘
- Logging:日志查看、设置
- Core Admin:内核管理菜单
- Java Properties:Java属性浏览
- Thread Dump:线程转储
- No cores available:包含的内核列表
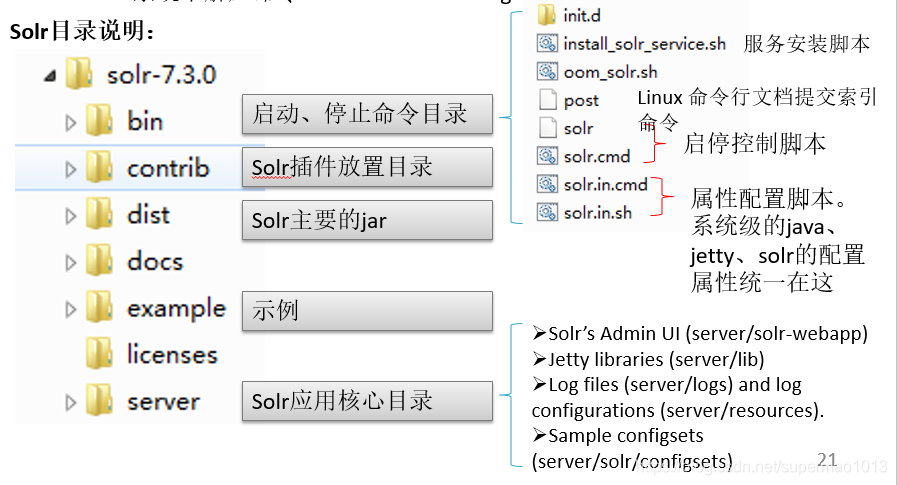
Solr目录说明
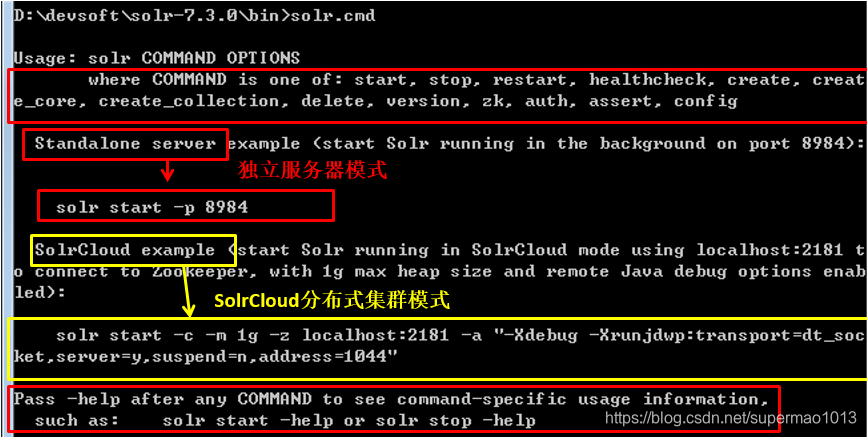
启停控制脚本支持的命令
Solr基本使用
Solr core介绍
在使用之前,先理解Solr core的概念。
core内核:是运行在Solr服务器中的具体唯一命名的、可管理和可配置的索引,即内核就是Lucene中说到的索引。一台solr服务器可以托管一个或多个内核。 不同的文档拥有不同的模式(字段构成、索引、存储方式),如商品数据和新闻数据就有不同的字段构成以及不同的字段索引、存储方式。就需要分别用两个内核来索引、存储它们。 内核相当于传统数据库中的表,文档相当于传统数据中一行一行的数据。创建内核
方式1 命令行创建
说明:
- -d选项可选值有两个:_default(默认值,最少配置)和sample_techproducts_cnofigs(示例的配置)。这两个可以在安装目录server\solr\configsets下查看到
- 如果默认的两个配置不满足要求,可以自己修改后放到server\solr\configsets目录下,进行重命名,然后-d指定这个配置名称
- -p选项表示指定哪个solr实例上创建,比如一台机器有两个solr实例,端口号分别为8983、8984,则使用-p进行指定,若不指定则默认为第一个实例
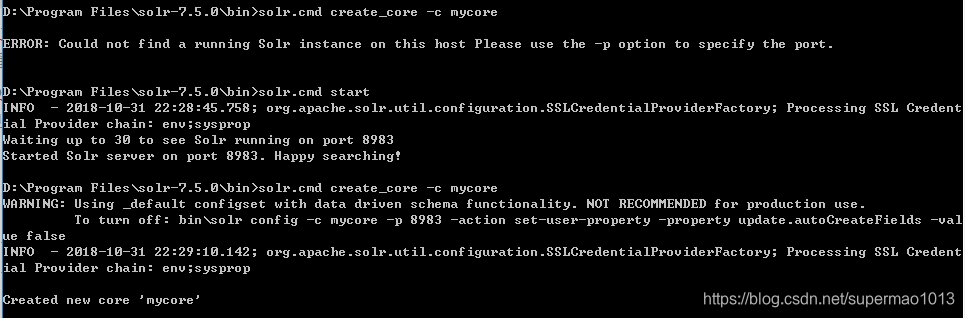
#windows下创建solr.cmd create_core -c mycoresolr.cmd create_core -c mycore1 -d sample_techproducts_configs
 登陆web控制台查看:
登陆web控制台查看: 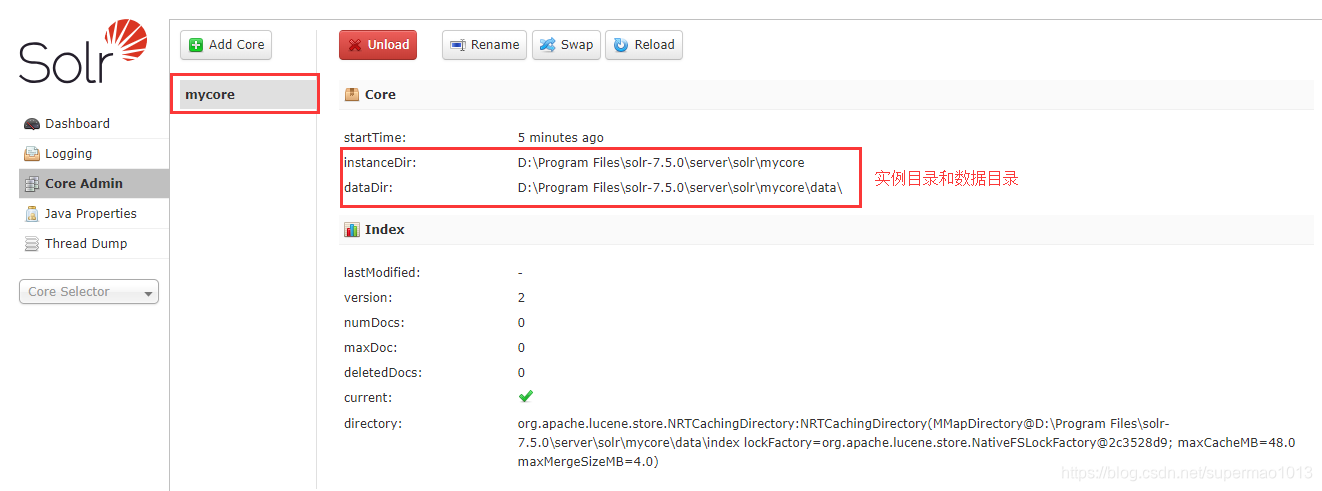
方式2 web管理控制台加载已存在的内核
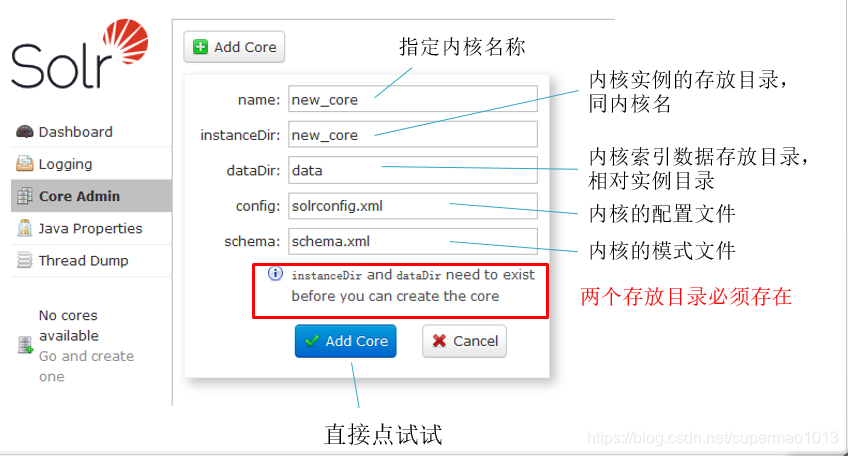
添加测试数据
命令行方式添加
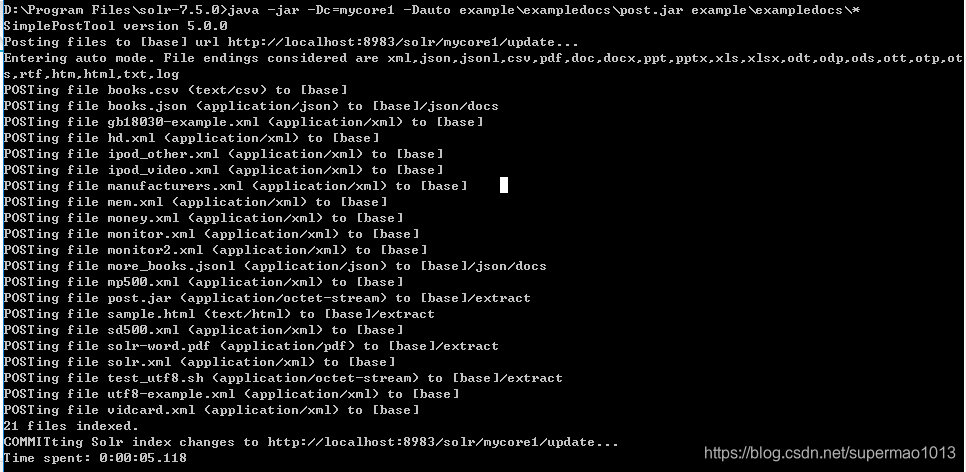
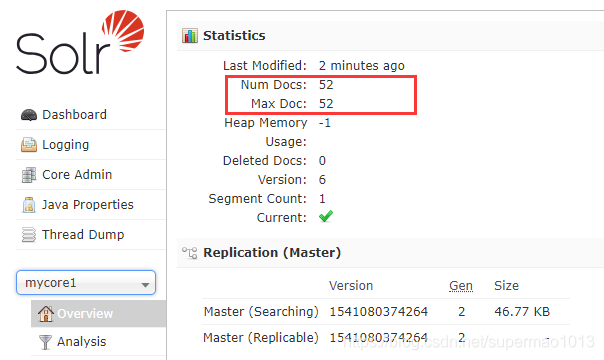
进入Solr安装主目录,输入如下命令:
#Linux/Mac命令bin/post -c mycore1 example/exampledocs/* #Windows命令java -jar -Dc=mycore1 -Dauto example\exampledocs\post.jar example\exampledocs\*
- -c和-Dc 表示指定哪个内核
- example/exampledocs/* 表示该目录下的所有文件都导入,Solr提供了很多样例文件,我们直接使用该文件进行导入
- -Dauto 表示自动模式,支持xml、json、csv、pdf、doc、xls、ppt文件的导入
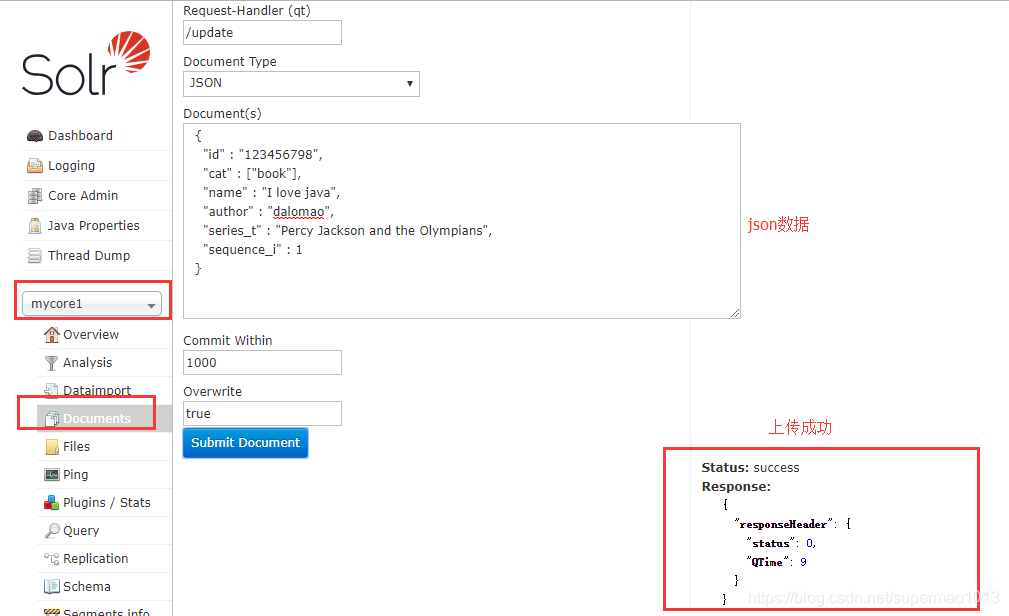
web界面添加数据
使用post请求
Web界面查询
原理:使用http get请求
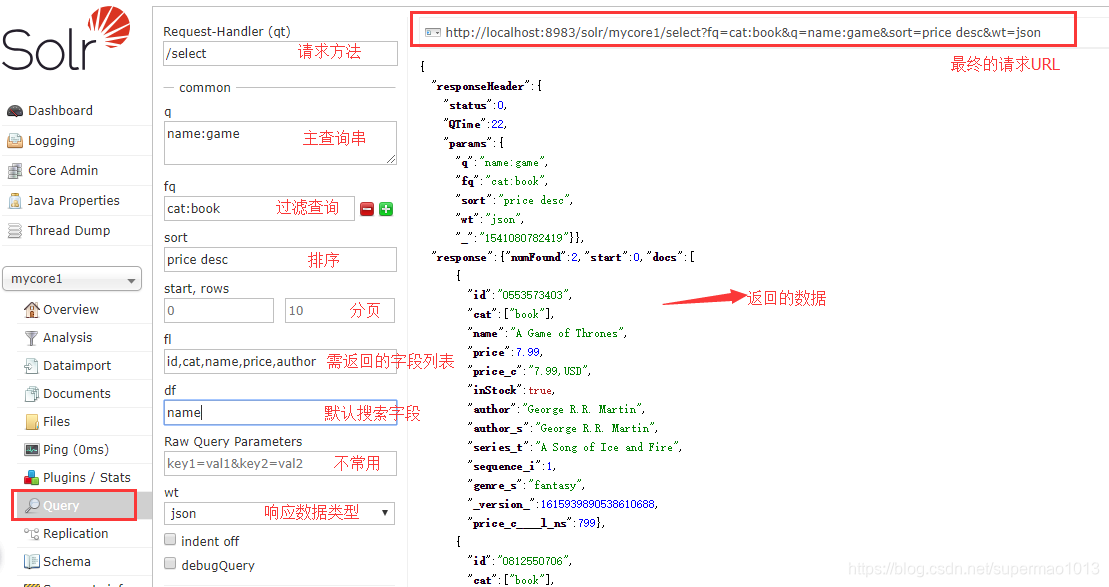
转载地址:http://bgsxi.baihongyu.com/
你可能感兴趣的文章
2017(第十届)中国绿公司年会马云演讲
查看>>
李彦宏:睡不着觉不是因对手
查看>>
从手Q与微信之争,看腾讯内在的真实矛盾与战略
查看>>
移动互联网的七宗败案
查看>>
互联网十大失败案
查看>>
小米颓势已现,生死劫命悬手机
查看>>
三大隐忧 三星未来路在何方?
查看>>
linux下各种进制转化最简单的的命令行
查看>>
结构体和联合体
查看>>
ACM(Association for Computing Machinery )组织的详细介绍
查看>>
unix高级编程之-命令行参数(实践一)
查看>>
无线网络加密方式对比 .
查看>>
linux中cat命令使用详解
查看>>
Static 作用详述
查看>>
透析ICMP协议(三): 牛刀初试之一 应用篇ping(ICMP.dll)
查看>>
透析ICMP协议(四): 牛刀初试之二 应用篇ping(RAW Socket)
查看>>
再次写给我们这些浮躁的程序员
查看>>
Linux下重要日志文件及查看方式(2)
查看>>
Ubuntu系统root用户密码找回方法
查看>>
Linux驱动程序中比较重要的宏
查看>>